Ever since the industry started adopting incremental deliveries instead of the waterfall approach, making sure the product delivers the most valuable features at the right moment has become more critical: 45% of IT companies suffer cost overruns due to unclear objectives, lack of business focus, unrealistic schedules and reactive planning. Assuming we have a solid time and cost estimation, the first question that arises is: What should we do first?
“It’s not always that we need to do more but rather that we need to focus on less.” (Nathan W. Morris)
It’s so critical to find a balance between the desired project scope, schedule, budget, staff and quality goal-constraints. This article presents a simple strategy to rank the work to be done based on business value, cost, and risks.
Check out a TL;DR version of this article with an epic cheat sheet to download!

Before I start, let’s define some basic concepts and anti-patterns.
Prioritisation and priority
The first problem in most requirement prioritisation processes is the ambiguous definition for the terms “requirements prioritisation” and “priority”. Why? For certain companies, “requirement prioritisation” may refer to what is more important, while for others it might mean what should be implemented first. This lack of standardised definitions creates confusion and misunderstandings amongst product development teams, provoking useless discussions about importance, urgency and implementation order of tasks.
In this article, a prioritisation process is defined as a requirements triage: The process of choosing the right requirements that satisfy a set of criteria to be included in the next release of your product.
Based on this, a priority is a ranking attribute of a requirement or task that results from a prioritisation process.
Now that we understand what the terms prioritisation and priority are, let’s take a look at the most common anti-patterns.
The common anti-patterns to avoid
Prioritising by business value only
Customers and business representatives will always push the development team to perform the “most valuable” tasks first. However, certain tasks require more technical effort and if we develop them at the beginning, we might create unwanted side effects such as:
- Blocking valuable features: When the technical complexity is not taken into account, our team might start working on complex features, blocking easy tasks that, taken together, could generate more value than the others.
- Technical debt: To preserve our team’s velocity regardless of the complexity of tasks, technical shortcuts will be taken. In the end, this behaviour produces technical debt which in turn affects the product quality and our team's future velocity.
Rule of thumb or previous experience-based prioritisation
Our experience is, of course, valuable and will always play an important role during any prioritisation process. However, prioritising only based on experience or gut feeling is not a useful engineering method. Most of the time, this approach creates biased results and removes the objective mathematical layer that a good engineering process provides.
I have seen managers and product owners choose and organise features without consulting the team or tech experts. This attitude can provoke a lack of trust amongst the team and risks creating false expectations in the stakeholders.
Basic prioritisation methods
"Everything should be made as simple as possible, but not simpler." (Albert Einstein)
There is no unique prioritisation method and much less a bulletproof one. That’s why I want to present some simple, popular and powerful methods that will help us for small and low-risk projects.
Ranking by business value and technical impact
This is one of the first methods that I learned about. Even though it was designed to prioritise Architecturally Significant Requirements (ASR) in a software architecture’s utility tree, it’s also a good approach for smaller scenarios.
The basic idea is to prioritise your task by assigning a qualitative score (high, medium or low) to the business value and technical impact (complexity). For instance, assume that we have a feature like: “Accept Cash Payments”. In that case, a possible output could be:

In the end, you’re going to prioritise the tasks with the highest business value and lowest technical impact.
Benefits
- Simple
- Takes both technical and business perspectives into account
Pitfalls
- Repetitive values in big projects
- Hard to coordinate all stakeholders to choose a value
- Not clear if both criteria have the same weight
- Ambiguous and limited for big projects
MoSCoW method
This is one of the most simple and common methods for task prioritisation. Developed by the software engineer Dai Clegg, its name is an acronym for the four possible priority classifications for the requirements.
-
Must: This requirement is critical and needs to be done to consider the solution a success.
-
Should: This is an important requirement and should be included but it’s not mandatory for the project’s success.
-
Could: This is a desirable feature but only if time and resources allow it.
-
Won’t: This task won’t be implemented this time around but could be included in the future.
In practical terms, a MoSCoW prioritisation could look like this:

As you can see, the must-have features are at the top, while the won't-do features live at the bottom. It’s clear that prioritising features with the same score could be difficult for big projects due to the repetitive nature of this method.
Benefits
- Simple
- Forces the stakeholders and members to “throw the garbage away”
Pitfalls
- Division between business value and technical complexity not clear
- Non-M requirements are hardly done (especially in agile environments)
- Unclear how to prioritise between different M-tasks
100 Points / $100 method
In this method, each team member gets a budget of $100 and needs to decide which features they want to spend it on. In order to take the technical complexity into account, some variations consider the effort to achieve a specific feature as the cost. That means that more complex features have higher costs, forcing the business representatives to use their money wisely.
A good way to think about the price of our features is to use relative measures such as T-shirt sizes or story points (SPs). If you use the latter, each SP could, for example, represent $1 - you decide on the exchange rate. That means the complexity of a feature defines its basic cost.
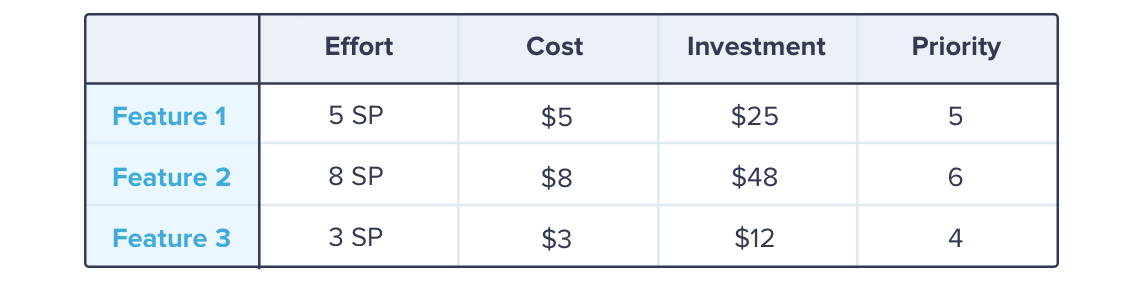
If a team member wants to invest in a feature, they have to at least spend the SP-related amount of money on it. They could also spend more if they wanted to rank a particular feature higher. Once every team member has invested their budget, the priority ranking is calculated by dividing a feature's total investment by its basic cost.
Benefits
- Simple
- Forces the team members to rank and “throw the garbage away”
Pitfalls
- More often than not, the business value of a company is measured through money. However, sometimes intangibles assets such as data quality, code quality and architecture could represent more value or enable other features.
- People could negotiate their money and create alliances that benefit participants’ particular interests instead of considering the real business value.
- Risk of someone allocating all the money into a specific task, which would be pushed to the top and change the team’s perceived value of certain requirements.
Prioritisation by value, cost & risk
The previous techniques are simple, informal and entertaining options to prioritise our tasks. Nonetheless, most of them might have core problems for big and high-risk projects. For those cases, we need more analytical options that can help us avoid ambiguity and subjectivity.
That’s why my default choice is to prioritise by value, cost & risk, one of the top-ranked methods for prioritisation.
In my experience, it's a simple and efficient method that reduces ambiguity during the prioritisation process and provides a decent mathematical basis for your results. Let’s stop talking and go hands on!
Value
The criterion “value” describes the relative business value that a feature, user story or functional requirement will provide to your business. In this method, the value is the sum of:
- the relative benefit that a specific feature will provide to the customer or business and
- the relative penalty that the customer or business will suffer if a specific feature is not included.
This value can be visualised on a spectrum:
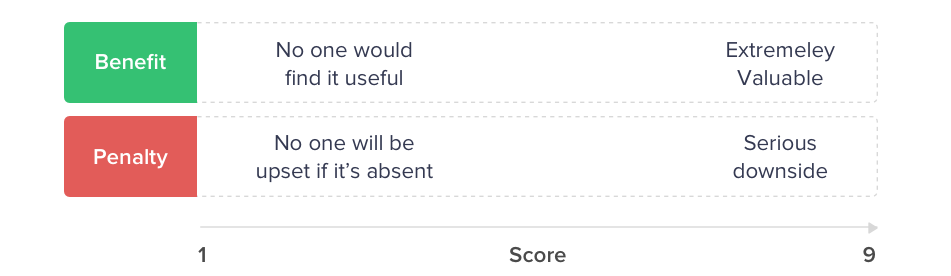
It’s common to see features where the benefit is low but the penalty is high: Even if these features are not going to give the customer or company a real benefit, the penalty of not having them can provoke serious damage to the business. Good examples of such features are privacy and security standards, contractual requirements and regulatory compliance.
Cost
The cost describes the relative cost or effort of implementing a specific feature on a scale from one (quick and easy) to nine (long and complex). If you’re working with agile methodologies, you can use story points or any other relative measure. I've described how to do this in my previous article on time and cost estimation for software projects.
Risk
The main risk of this method is the probability of not getting the feature right the first time. In the authors' own words:
“1 means you can program it in your sleep. 9 indicated serious concerns about feasibility, lack of expertise, unfamiliar technologies or concerns about complexity” (Wiegers & Beatty)
Usually, when using SPs, you've already taken technical risk into consideration. That means you could theoretically leave out the "risk" calculation altogether. In my opinion, it’s always good practice to keep this criterion isolated because it gives more visibility to all the concerns.
Calculating the priority
Now that we understand the method’s criteria, we need to evaluate each feature. For this purpose, we are not going to use the raw values we have assigned, but instead, normalise them through a ratio scale. We divide each value by the sum of all the values, resulting in a percentage. So for each criterion, we can define:
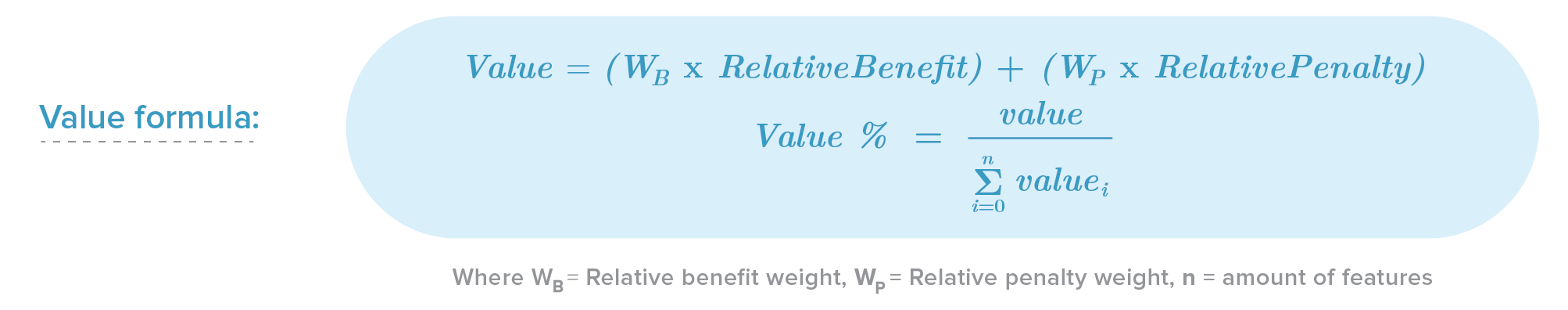
As you can see, we need to define a relative benefit weight (WB) and relative penalty weight (WP). Those values represent the level of importance with respect to each other. That means, if you assigned the value "1" to WB and "2" to WP, you are saying that the relative penalty is twice as important as the relative benefit.
You can use your own score to define those numbers and base them on your experience and business expectations. If needed, you can also use more formal methods.
Finally, this formula will give us a number that represents the position or ranking of our feature in the list:
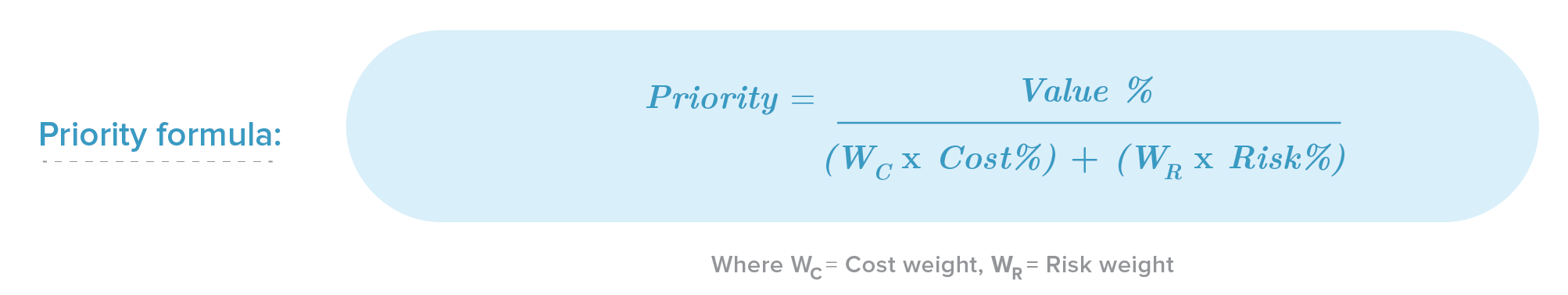
Similar to the value formula, don’t forget to assign a weight or level of importance to the cost (WC) and risk (WR) with respect to each other. The cost and risk ratios, on the other hand, are calculated in the following way:

A quick example
The easiest way to calculate our priority numbers is to use a spreadsheet. The following table is an example of a prioritised list of features using the value, cost & risk method. Please note that in some cases we might have high-value features with low priorities and high-risk features with good priorities.
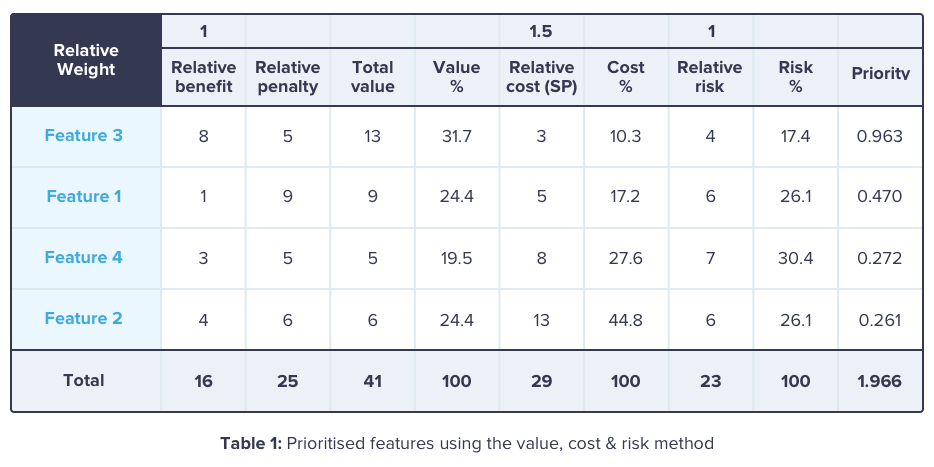
The reason for this is that we are balancing the criteria via weights changes, calibrating the model according to our needs. That's why I've prepared a template that you can download and use for your own projects.
Final tips
For small and low-risk projects, the basic methods presented in this article are good and entertaining options to go for. If you have a bigger and more high-risk project and decide to go with prioritisation by value, cost and risk, please keep in mind to:
- Group by capabilities and dependencies: There are certain features and tasks that depend on each other. In most cases, it’s a good idea to group those related or co-dependent features. For instance, if you have a list of features like login, signup and log out, you can group them into the feature "Implement authentication life cycle".
- Define multiple spreadsheets for different granularity and abstraction levels: Do not mix projects, user stories, use cases or functional requirements, they belong to different levels of abstraction. For instance: You can create a spreadsheet to prioritise your IT projects and have a spreadsheet for logical components to implement for each of those projects. In addition, you could have a spreadsheet to prioritise the features for each of those components - you get the point.
- Always review the final results: This is a non-rigorous mathematical approach, so sometimes it can generate scores or rankings that might not make sense in your specific context. For these kinds of cases, you can calibrate your model (change weights) or, if the issues are few, perform manual changes.
- Group by stakeholders: It’s possible that certain stakeholders or group inputs are more relevant than others. If needed, you can create new benefit and penalty columns for each stakeholder or group with their specific weights.
Resources
Rigorous mathematical models:
Methodologies with interesting prioritisation methods:
This article was written by Juan Urrego - Software and solutions architect with thorough hands-on experience of software engineering, software architecture and agile development. He has entrepreneur, IT consulting and university lecturer experience with high emphasis and interest in AI and machine learning.
We have started collaborating with South African software makers to share their insights, learnings and ideas on the blog. If you have an interesting topic in mind and are keen to write with us, please get in touch!