More and more businesses are becoming technology-reliant companies. In one way or another, they generate value through technology and tech tools. Using DevOps can help companies produce faster with more reliability and stability. But first, we need to understand what DevOps is. Here I will introduce some key concepts in DevOps and talk about how they helped me.
What is DevOps
The world and its different sectors (from retail to entertainment to industry to accounting) have been altered over the years by software and the Internet. Software nowadays plays a crucial role in every aspect of a business, surpassing simply providing an application. In addition to the "normal" software development, industries transform every step of the value chain to improve operational efficiencies. DevOps bring new ways to produce and distribute software and help industrial automation throughout the 21st century.
So, you may be asking: "What the hell is DevOps?". DevOps is a methodology used in the software development and IT industries. Overall, it is a set of practices that integrates and automates the daily work of Development (Dev) and IT Operations (Ops) to enhance and shorten the systems development life cycle.
From my personal experience as a full stack engineer and Scrum Master, I realised how important DevOps is when I joined Nmbrs and started reading books and articles explaining the importance of DevOps, the core concepts to apply it correctly, and real-use case studies. In this article, we will discuss:
- The lean operations
- The technology value stream
- The principles of continuous learning and experimentation
- How this theory helped me as a developer and Nmbrs.
DevOps follow lean operations principles
Lean operations is a lead strategy for improving internal functions, developing a productive and engaged workforce, and increasing profits. The term "lean" refers to a business management approach focused on providing the most value to the customer while using the resources effectively. Cutting costs and operating more efficiently should be top priorities no matter what type of business you are in.
The lean philosophy is based on the following principles:
- Eliminate waste
- Build quality in
- Create knowledge
- Defer commitment
- Deliver fast
- Respect people
- Optimise the whole
When you think of DevOps, you can think about it as a lean principle.
The Technology Value Stream
One of the fundamental concepts in lean is the value stream.
In their book Value Stream Mapping, Mike Osterling and Karen Martin define the value stream as "the sequence of activities an organisation undertakes to deliver upon a customer request" or "the sequence of activities required to design, produce, and deliver a good or service to a customer, including the dual flows of information and material".
In terms of the technology value stream, this definition refers to the process of developing a piece of software. In this subset of the value stream, there are three key metrics to keep in mind:
- Lead time
- Process time
- Percent complete and accurate (%C/A)
Lead time vs processing time
Lead time is what the customer experiences. It measures the time between the creation of the request made by the client and the deployment of it. The processing time is the amount of time between when the work starts and when you complete it.
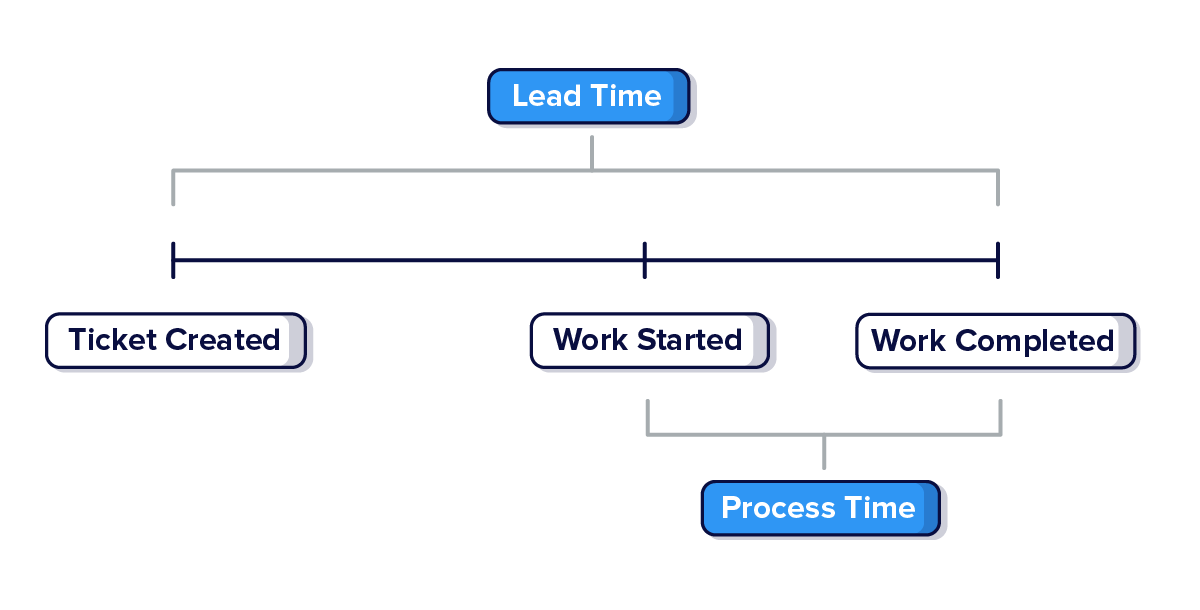
Companies often focus on improving their process time to reduce the speed of work as much as possible. However, they forget to take the lead time into account. The common scenario is that the deployment lead times often require months, yet only a part of that time is spent on actual development work, and the customer ends up waiting longer than necessary for the entire process to be completed. This means that the lower the lead time and process time, the better the process is defined. On the whole, if you deploy faster, the customer will have positive and valuable feedback for your company.
Percent Complete and Accurate
In addition to lead and process times, the third key metric in the technology value stream is percent complete and accurate (%C/A). This metric reflects the output quality of each process. To measure it, you need to ask downstream consumers how much of the time they receive work that is "usable as is" without having to correct it or contact support. If you don't need to rework anything, then the %C/A is 100%. If you have to fix a few bugs, then the percentage will be lower. For instance, if you had to rework 25% of everything, then the %C/A would be 75%.
The lower the percentage is, the more you have to rework. Even a small change affects the whole development team and the roadmap of the company. A high %C/A means that the whole process is going smoothly for the customer, the stakeholders, the product owner, and the development team.
Now you must be asking, is it possible to improve the value stream? If so, how?
How to improve the technology value stream
Shorten the lead times
This can be done by getting the support agents and product owners (or project managers) to work more closely together. This will lead to more knowledge being shared between the two groups, and if an incident happens, the support agents will be the first to know. Then, by asking for help from the product owners, they could come up with the necessary measures to fix the incident as soon as possible. The product owners should always know what they currently have in their backlog and prioritise the incident to fit in with their backlog.
Limit works in progress (WIP)
Too many WIP can lead to delayed process times as developers are working on multiple tasks at once. If each developer works on only one task at a time, it will be easier to identify possible problems that prevent the completion of work. You will also have more transparency on what is being done if you have only one task in progress assigned to one person. The Agile / Scrum Master should keep in control the amount of work that is in progress. If you don't have one, it should be the role of the Project Manager.
Reduce batch sizes
The difference between large and small batch sizes is dramatic (see the figure below). Suppose each of the four operations takes ten seconds for each of the ten envelopes. With the larger batch size strategy, the first completed and stamped envelope is produced only after 160 seconds. While with the smallest batch, it is 40 seconds. This is a time reduction of 75%.
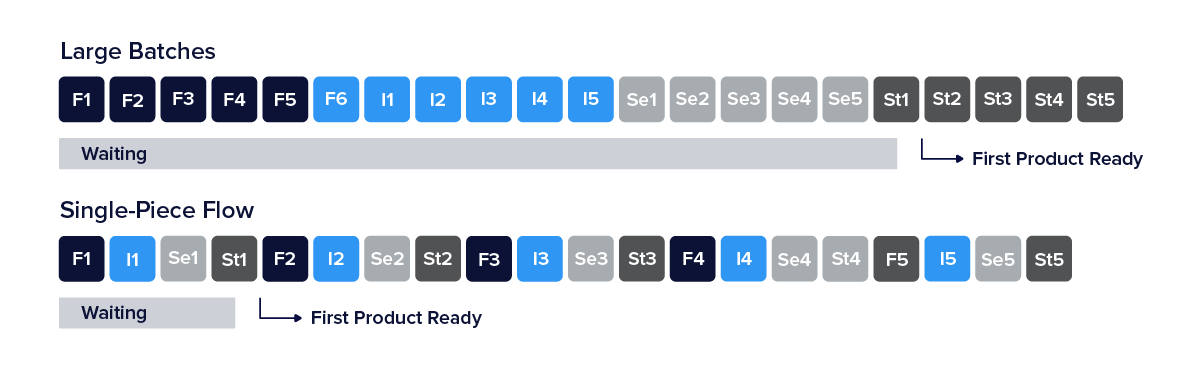
Small batch sizes result in less WIP, faster lead times, faster detection of errors, and less rework.
Reduce scrap and reworkings
In other words, reduce the amount of unfinished work and work you need to do again. The team should ensure more quality through their development cycles (at Nmbrs we work with sprints) by fixing issues as they arise. For example, you can use Sprint Reviews to receive feedback from stakeholders and clients, and if they don't like something, change it right away. Besides that, the developers should work more closely with Quality Assurance. Once the task is finished, ask Quality Assurance to test it. It shouldn't be the developer who did the work to proceed with the test.
The Principles of Continual Learning and Experimentation
As you can see, implementing the concepts of DevOps can be beneficial to improving the way a software company operates, but when you start changing the development process, issues will always happen on the client side or server side. The root cause is often deemed to be human error. However, we don't need to "name, blame, and shame" the person who caused the error. The management team's response should not be to point fingers. Once you blame someone, the organisation will start to face fear. They will be dishonest and less prone to test new technologies and frameworks. This is where the principles of continual learning and experimentation come into play.
Enable organisational learning and a safe work culture
When accidents and failures occur, rather than looking for human error, we must look for ways to redesign the system to prevent the accident from happening again. Local knowledge is created within an organisation by learning from successes and failures. By enabling organisational learning, you create a safe environment so people can grow. The growth of the team members will automatically cause the organisation to grow.
Institutionalise the improvement of daily work
In the technology value stream, when we avoid fixing our problems by relying on daily workarounds, our problems and technical debt accumulate until all we are doing is performing workarounds, trying to avoid disaster, with no cycles left over to do productive work. This is why Mike Orzen, author of Lean IT, stated, "Even more important than daily work is daily work improvement."
The leader's job is to set up the environment for their team to find excellence in their routine tasks. By expressly reserving time to eliminate technical debt, fix bugs, and refactor and enhance problematic areas of our code and environments, we improve daily work - allowing us to spend the rest of our time focusing on more valuable tasks, such as building new features.
Transform local discoveries into global improvements
There must be a mechanism in place to allow the rest of the company to use and profit from newly discovered knowledge when it is discovered locally. In other words, transform local learnings into global improvements. At Nmbrs, for instance, we use Jira Confluence to discuss the most recent discoveries.
Fortunately, I had the opportunity to work in two different industries: a software company and an analytics consultancy firm. The first one uses Scrum and has no managers. The second is still a traditional consultancy firm with partners, project managers, consultants and business analysts. When a failure occurs, both manage things differently. At Nmbrs, when we finish a new fix version, we do a retrospective on what happened and what we still need to improve. At the consultancy firm, we didn't talk at all. As you might be guessing, the same error does not occur a second time on Nmbrs, and at the consultancy company, the error could happen multiple times.
There are three questions to answer in those retrospectives:
- Stop Doing - What didn't go well?
- Continue - What did go well?
- Improvements - What was the solution, and what are the action points?
If you want to go deeper into the root cause, here are some further questions to answer:
- What was your last step, and what happened?
- What did you learn?
- What is your condition now?
- What is your next target condition?
- What obstacles are you working on now?
- What is your next step?
- What is your expected outcome?
- When can we check?
A few months ago, at Nmbrs, we had a code-red situation. In tech companies, we define code red as a feature or multiple features failing due to a microservice or a server going down. After we came up with a quick fix, the fixing team gathered to have a retrospective to log the root cause and discuss the next steps. It was a 20-minute meeting. You don't need much more than that.
As a Scrum Master, I had to facilitate the retrospective and send the fixing team the template to fill in the three questions I shared above. When we went to the meeting, they already had it prepared beforehand. I gave 5 minutes to discuss each question and, in the end, another 5 minutes to talk about the future action points. It helped us solve the issue right away, and until now, the situation hasn't happened again. So we believe it was a successful retrospective.
How DevOps theory has helped me
DevOps theory has helped me to understand what was missing at my previous companies and how implementing DevOps at Nmbrs has improved the company workflow. When we started moving from a Monolithic application to a Microservice approach, the clients and the development team felt the changes. The clients felt the improvement in the lead time and the request server time. The development team can work better and faster with microservices since it is easier to work with them.
Conclusion
By adapting the current process to improve the technology value stream, you will deliver faster and more often with less work. In addition to that, DevOps will help you produce faster with more reliability and stability.
Remember that by removing blame, you remove fear inside your organisation, and by removing fear, you enable honesty and enable people to grow. By people growing, you enable prevention and quality. Keep this in mind if you want your organisation to go a step further compared to your competitors.
DevOps is currently one of the most discussed software development approaches. While this article covers the basic theories and how we can learn from them, there are still multiple concepts and methods inside DevOps that may or may not apply to you and your company. That is why in the next article, I will be speaking about where to start when you are trying to implement DevOps in your organisation.
Resources
- The DevOps Handbook, by Gene Kim, Jez Humble, Patrick Debois, John Wilis
- Value Stream Mapping, by Karen Martin, Mike Osterling
- Lean Software Development: An Agile Toolkit, by Mary and Tom Poppendieck
- https://aws.amazon.com/devops/what-is-devops/
- https://www.atlassian.com/software/confluence
Guilherme Pinheiro is an energetic and enthusiastic engineer. He is a Full Stack Engineer and Scrum Master at Nmbrs. Outside of his professional life, he is a sports lover.
Read More
- DevOps Engineer Salary Trends in Germany
- DevOps Engineer Salary Trends in South Africa
- What to Consider when Building a DevSecOps Pipeline
