Software comes with bugs. It’s part of the deal, especially when you’re trying to ship an MVP quickly and improve from there. Even though it wasn’t in total shambles, our old process for handling bugs at OfferZen wasn’t optimised. This lead to a lot of distraction for everyone involved, which is why our Tech Team set out to design and implement a new bug solving process.
Our pains
For the longest time, our 9-person strong team handled bugs like this: Every week, two developers would be on bug-duty. If a bug or platform question came up, they’d try to fix it themselves or ask someone else to assist. If things got a bit crazy, our product lead would step in: he’d either help us solve it or reprioritise it. As a developer on bug-duty, one minute you would be working on a new feature. The next, you’d have to switch to a different part of the app, in a different language, to fix a bug. This caused quite a few pain points:
- Distraction from planned work: This could get so distracting that we’d sometimes have days where those developers weren’t able to get any planned work done.
- Lack of delegation to the relevant expert: In some cases, the bug-duty developer wasn’t the expert on the problem. While we did value the benefits of this cross-pollination, it still had a big effect on the time spent trying to solve a problem. Without specific delegation, it took longer than necessary to fix the bug. It could also have more subtle side-effects, such as making the developer frustrated.
- Missing out on valuable insights: We also weren’t doing much in the form of tracking, aside from remembering that certain bugs existed. We were missing out on valuable insights into the areas of the code which were causing the biggest problems. This meant that, when we were talking about patterns or problematic areas that we’d noticed, we could only go on our hunches and anecdotes.
Our goals
Once we had identified the pain points that we experienced under our old process, we could draw up a shortlist of goals for improvement:
- Our main priority was to reduce the noise that we received from bugs. We wanted to receive fewer Slack messages from Bugsnag, as that often broke our attention to our current work. At the same time, we needed a defined process that, when a message did come through, we knew what to do and could handle it with minimal distraction.
- Better tracking of bugs was also a priority, so that we could gather some real data. Data on affected users could help us prioritise the importance of a bug better, while labelling bugs could help show patterns which, in turn, could help us decide which parts of our application needed the most attention at that time.
- We also aimed to speed up the resolution of the bugs for a better user and developer experience. Reducing the repetition of mistakes and improving release quality were also priorities, as these would have a compounding effect on reducing the noise from alerts.
And to top it off, we wanted to do all of this faster to get on top of a bug situation as soon as possible. In our minds, this would lead to a cleaner code base, better developer knowledge, more job satisfaction for our developers, and a better experience for users.
How we did it
Introducing versioning
Using our CI, we started tagging any deploy to production with a version number. This unlocked some great bug tracking opportunities in Bugsnag: it would give us an idea of what the codebase looked like when the bug first appeared, or when something went from an annoying bug to a wildfire of 500 errors. While correlation didn't mean causation, it usually offered a good place to start looking. This set us up well for investigating and solving issues. We still need a way to assign and prioritise them, though.
Building a process for assignment and prioritisation
Enter our bug triage process. If you've been to a hospital's emergency room, you may have already encountered a triage system in action. The triage nurse assigns a prioritisation level and relevant department to each patient. So, if a patient comes in with a stab wound to the chest, they might get rushed into surgery. Little Timmy, by contrast, would be asked to wait in the queue for a bit longer as the fish bowl stuck over his head isn't as life threatening as he thinks. Luckily for us, we didn't have to deal with stab wounds — just validation errors!
Below is a diagram explaining the new bug triage process that we implemented:
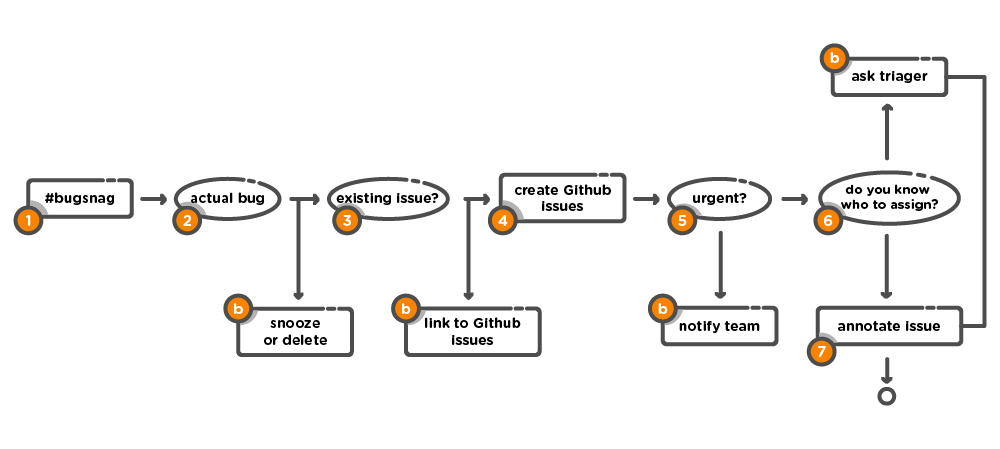
- We receive our bug alerts from Bugsnag via a Slack integration. When an alert comes in, the person on bug duty is responsible for looking at the message.
- They'll have a quick look at the error, and if it's obviously not something that we're concerned about (for example, an error that we triggered intentionally) then they can ignore it.
- Then it's time to have a quick look to see if it's an existing issue. We talk about bugs openly when they occur, so we all tend to know what's going on. If it is an existing problem, then it will be linked to the existing GitHub issue on our repository.
- If not, the next step is to create a new issue on GitHub. Bugsnag automatically does this for us and provides relevant details.
- The next step is to decide on the urgency. I could go on for a while about all the various factors, past experiences and gut feelings that can go into making these decisions, but some of the main questions that we ask are: (i) Does it break a feature? (ii) How many users are affected? (iii) Are they internal or external users? So, if we see that one of our main features (e.g. Interview Requests) is having issues, then we know that this affects all candidates and companies on the platform. It is a major feature that needs to work at all times. That means we must alert the team so that they know that this is now our primary focus.
- If it’s a less severe bug that doesn’t require immediate attention, then we can allocate it to the team that knows the relevant feature or code. We do this via GitHub projects, so that we don’t have to try to maintain multiple sets of information about the issue. It is also allocated a priority: either “high priority” or “low priority”. With high priority bugs, the relevant team will plan around their current mission and try to have it resolved within three days.
- Finally, we will continue to add information to the issue as we encounter it. This documentation is valuable for when the developer start working on the bug.

A Look into the Future
After a few weeks of testing out this solution, we've found that it does help with the distraction of fixing bugs in general, as the work can now be planned into the developer's day. Although the distraction from bug alerts has yet to go down, this is something that we see as more of a long-term goal. This feels much more achievable now, since we have data to guide our decisions. We've only been using this for our main product, so the next step is to roll this out to our smaller apps and services.
Bugs are definitely being solved at a faster rate now, with each developer aiming to solve at least one per week. We also have much better bug tracking, as we're able to tag and comment on the GitHub issues. It helped us keep better track of ongoing discussions around bugs, as well as their potential causes and fixes.
Main takeaways
These were our main takeaways from implementing and testing our new process:
Look at how many users the bug affects: For example, if we saw a bug come through that only affected one user, then we'd be less likely to give it a high priority.
If you're having trouble, ask your teammates first before reassigning it: When someone is assigned a bug to fix and they're having a tough time solving it, it means that we didn't assign it properly. However, it's still quicker to resolve if that developer then asks the team for help instead of putting it "back on the pile" to be reassigned.
Some bugs have multiple sources: It can be really frustrating when you fix some code, only to have Bugsnag alert you again a week later. In these cases, it's important to stop, talk to the team and rethink the problem to help split up the concerns into manageable tickets. The lesson we learnt about looking at affected users could also be applied here to help resolve it.
If someone offers to handle a bug, let them; they know what they are doing: When someone stands up and offers to solve it, this should be the most important factor when assigning as they know what the problem is, and how to go about solving it.
If you can't find it, make it: Since we were using GitHub issues to track all of this and then pull requests for code reviews, we noted that it didn't have the ability to tag the user in Slack when they were tagged in a comment. We hunted around for a few options, and while we found some, they were either unnecessarily expensive, or unmaintained. We mostly use Ruby on Rails in house and it's great for quickly spinning up an application; particularly one with integrations as there's probably a gem available. So we decided to go with Rails. Our app just matches up GitHub handles to Slack handles and forwards the message to Slack while tagging the relevant users. We called this Gina's Desk, after the crazy character from Brooklyn Nine-Nine who (when she does her job) allocates cases to staff in the precinct. She is also the face of most of our bug related notifications and integrations.

Clive is part of the Tech Team at OfferZen.
