Most developers will find themselves working on a legacy project at some point in time. These projects tend to come with many "code smells" or "anti-patterns" that feel so large they seem insurmountable. In this article, I will be discussing five such anti-patterns that my team identified over the course of a year, and how we went about making small, incremental changes to address them.

I spent a good part of 2018 working on a mature .NET project. The project had a history that was at least eight years old, but extended even further back to when Subversion was used instead of Git (yikes!). I worked in a team of consultants that was contracted to add new features. Crucially, these had to be added without interrupting the functioning of the existing system, since the site had thousands of concurrent users at any given time.
The company could no longer internally allocate the people necessary to run the project since their efforts were focused on newer projects, and so we filled the gap that was left behind. The existing team had previously tried to work with consultants, but personalities had clashed and relationships had gone sour. That meant we were not only fixing code; we were also rebuilding trust and mending a few broken bridges.
Very early on in our involvement, we identified that some of the aspects of the existing software solution were less than savoury. It would have been easy to accept these as the status quo and just focus on our brief. However, we needed to prove our ability as new members of this existing team. Our strategy for demonstrating our value was threefold: we wanted to increase site maintainability, stability and extensibility.
In the end, we were able to successfully increase the overall code quality of the project, despite what we were up against. I will now elaborate on five of the major problems that we encountered and how we tackled them.
The Five Anti-Patterns
Fragile Database Code
Code that interacts with data stores is often unreliable. This is a natural outcome considering that database code is both easy to hack together, and yet resistant to change. In our project, we had a number of concerns in this area.
To begin with, the project used static repositories extensively. Static repositories are classes with global scope, meaning that they exist for the entire lifetime of the application, and introduce statefulness where we may not necessarily want it. They expose functions that often just wrap direct access to the database, or call into functions and libraries that generate database queries. This is what we might call a "thin abstraction"; although, because we are not writing SQL statements directly, the complexity of the underlying database still needs to be managed by the developer. An example of a static repository may look like this:
Static repositories are bad news because they cannot be dependency injected, and so cannot be mocked. This makes them extremely difficult to test. The fact that they live in global scope also means that they are less configurable on a per use basis.
We also had a lot of database logic attached to data models. Similarly to static repositories, this code is difficult to test. Ideally, we would like to separate data and behaviour as far as possible. For instance, we can see this happen here if we place a 'Save' method in our customer class as follows:
The presence of database logic in these models leans towards conventions set by Domain-oriented design, where logic is centralised to the domain model rather than into disparate repositories and services. However, it significantly bloats your data models, particularly if you have not distinguished between the models sent to the front-end (that is, your Data Transfer Objects), and the models used to define your domain.
Long running refactoring strategies
Our team addressed these issues by creating what we termed a perpetual refactor philosophy. This is a commitment to increase the average quality of code by tackling individual appearances of larger problems on a per-instance-basis, rather than through large sweeping architectural changes. It would become a tour de force that our team would undertake over many months.
In practice, it meant that, if you were working on a feature that touched questionable code, you had free reign to refactor and improve it.
This revision work was incorporated into our project sprint estimations as part of the effort necessary for a new feature. In general, I feel like this was a great compromise: We could meet client expectations while reigning in the desire for developers to spend extended amounts of time improving otherwise working software solutions. Through consistent adherence to this practice we slowly, but constantly, improved the quality of all the code in our project.
With regards to the static repositories specifically, we created an interface and a corresponding concrete implementation. Here is an example of what we did:
Database code living in domain models could now also be moved into this repository. This made the repository dependency injectable, which allowed for proper unit tests to be written. I will expand on the fundamental importance of these kinds of tests in a later section.
Negligent Styling
Web applications come with the unique problem of CSS and styling. Like any mature project, our site had many pages, with many individually styled elements. The existing solution gave users a single payload for all the styling on the site, including parts that they were unlikely to visit as a first-time user.
As a result of how browsers have historically behaved, this was deemed to be the most logical approach by the web development community up until very recently. Developers were constrained by the number of requests available at any given time, which meant that they were incentivised to pack as much into a single request as possible. However, with the advent of HTTP2 and intelligent bundling provided by technologies such as Webpack, this is becoming less important. Furthermore, as these assets grew to be megabytes in size, using a single payload quickly became very costly in load-time and data usage for the user. A change was necessary.
The issue with CSS is that it exists, like JavaScript, in a global scope. So, styling is also hard to test, which makes it hard to refactor. If your project has a comment like this, which has been there for a long time, take that as a red flag:
Priority Stylesheets and CSS Preprocessors
Our approach to fixing this was to create a new priority stylesheet called min.css. This contained the bare-minimum rules to render our homepage. A user visiting our site would first be given this stylesheet, then an initial render of the page would occur, and further styles would be loaded asynchronously. Although this does not immediately reduce the overall download size of all stylesheets, it increases site responsiveness and opens the door to further work.
TIP: A great way to start creating a minimal stylesheet is to use an extension like CSS Used, which will tell you exactly what rules have been used to create the current page. You can use this as a base to construct a readable and maintainable stylesheet. Using a CSS pre-processor such as LESS or Sass can also dramatically increase code reuse, as well as provide you with some insight that will allow you to better reason about the styling in your project.
Unruly JavaScript
Like many mature web applications, the project that we were working on had accrued thousands of lines of JavaScript to control client-side behaviour and create rich interactive components. Like CSS, JavaScript exists by default in a global scope. This means that some scripts will eventually make implicit assumptions about objects and functions defined in other files, or have exponentially complex error-handling to ensure their existence.
This is what our project was facing: It was difficult to trace the origin of certain JavaScript objects, since there is no native way to establish which files correlated to which objects in their current state. This, of course, influenced the general ease of debugging. Additionally, we were required to target ECMAScript 5 (ES5) for browser compatibility. As a result of this constraint, we were unable to use new features which would have made the existing JavaScript more manageable.
Migrating to TypeScript
One great way to tame your JavaScript is to use TypeScript. TypeScript is a superset of JavaScript that adds static typing and a few additional features, such as interfaces, decorators and compile-time directives. TypeScript eventually compiles to JavaScript, but this extra layer of abstraction allows you to use modern web development techniques, such as lambdas, a.k.a. "arrow functions", and still target older browsers. TypeScript is backed by Microsoft, and their release schedule is way faster than waiting for the three or four major browsers to catch up to new web standards (if they decide to implement your desired feature at all).
The best way to demonstrate the benefits of TypeScript is through a concrete example:
This is the canonical ES5 way to define a class-like object. At first glance, it may not even look like a class to you, and that's because it really isn't. Rather, it's a verbose and unclear way to define a single object that encapsulates functions and data. These kinds of pseudo-classes were once all over the project, and they were incredibly difficult to understand, particularly those that were more than a few lines in length. In contrast, this would be the equivalent in TypeScript:
Not only is this cleaner and involves less typing, it also contains more information about the nature of the transactionHistoryRange function. From this definition we can see that the two parameters are dates. We also see that the function returns an array of objects that conform to the ITransaction interface. The JavaScript variant showed none of this.
Since TypeScript has a static type system, it enables productivity features like code completion in editors, dead-code and usage analysis, and compile-time optimizations. All this makes it very pleasant to work with. As part of our perpetual refactor philosophy mentioned earlier, we slowly converted all JavaScript files to TypeScript. In my opinion, TypeScript is a fantastic tool, and I simply cannot recommend it enough. You can learn more about TypeScript here.
Overbearing Manual Testing
In addition to these challenges, we inherited a large manual testing harness. In fact, our manual test-cases outnumbered our automated integration tests and unit tests combined. This seems contrary to the best practise, which is sometimes termed the "Testing Triangle". Jon Kruger, a software developer and Agile coach based in the US, describes this brilliantly.
In the past, the manual tests had been maintained by full-time software testers. As the team structure of the project changed, these testers were eventually moved off the project, and the responsibility for running these tests fell onto the developers. Working through these tests took roughly a full week out of development time. This meant that in any given sprint we spent between 30 and 50% of our time clicking through our site. These tests were also often outdated, and written by people who had little to no programming background. It was a necessary chore for the project, but it was certainly not development-oriented.
Prioritising Unit Tests
We addressed this by making unit testing a more deeply integral part of the development cycle. This was not strict adherence Test-Driven Development, but it turned unit tests into as much of a priority as the feature that we were developing. Unit tests were now inspected in code-review sessions and thoroughly critiqued by other members of the team.
Investigating automated front-end testing frameworks can also prove to be very valuable. These frameworks can remove a vast amount of grunt-work in establishing the presence of bugs without involving slower and more fallible human interaction. Although software projects can grow to be complex systems with many features, such applications generally seek to fulfil a handful of imperative objectives. For example, an e-commerce site may first and foremost be concerned with a user being able to add items to some kind of basket, and then complete a purchase. Thus, if we can establish whether these two core user interactions work, we have covered the vast majority of the client's concerns. Frameworks like Katalon or Selenium can increase confidence in your ability to deliver on the client's most essential requirements, while saving you the hassle of spending most of your time manually testing existing features. You can learn more about automated front-end testing here.
On our project, the manual tests never disappeared but our dependence on them for identifying bugs decreased.
By working through the manual tests less frequently, we were able to save upwards of three days every sprint, while still being confident that our releases were stable. This meant both happier developers and increased delivery to the client.
Monolithic Codebases
The final issue that we dealt with was the raw size of our codebase in megabytes. This was an issue that grew slowly enough that the people working on the project from the beginning never noticed it. The project had on the order of 697,000 lines of just C# code. A lot of this code was auto-generated, and most of it was not tested. The project was built entirely, and had all tests run, on every commit.
The result of all of this was a minimum ten minute time delay. This reduces what I like to call the "transparency" of work. That is, what I am doing now only affects what I see later. Initially, this does not seem serious: is ten minutes really all that much in the grand scheme of things? The answer is yes, it is. These delays acrete over time and the difference between waiting two minutes and waiting ten minutes can result in days of lost development time.
Breaking Your Project Into Smaller Parts
The remedy to this is to break your projects into smaller parts. Most projects can be split into two distinct sub-projects: a front-end, which is presentation logic and a back-end, your business logic. If your project has utilities or long-running integration tests, these are also good candidates for separating into a completely separate solution.
The general rule of thumb is that if it runs once a day or less, it can be extracted into a new solution. To borrow words from Michelangelo, "In every large project, there are a number of small projects desperate to escape." For example, pictured below is a fairly common solution structure for an ASP.NET MVC web application:
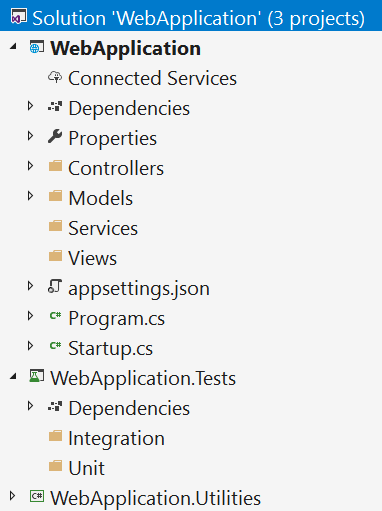
Here we find a main WebApplication project that contains all of the code the client is ostensibly paying us to maintain and extend.
We also have supporting projects for testing and infrequently run utilities. These utilities might, for example, be code that imports and transforms external data once a week, or generates quarterly reports.

By breaking our project up into smaller parts, we are essentially stratifying the parts of our solution into more concretely defined areas of responsibility. Although it may at first seem counter-intuitive, organising more projects in this way actually speeds up built-times rather than slowing them down, thanks to the change detection in modern compilers. Additionally this act of separation allows us to go another step further, as pictured below.


We now have two distinct solutions: WebApplication and WebApplication.Supportive. We have moved the slow-running integration tests and the utilities into a separate folder structure that can be managed by a separate Git repository. The unit test project, more frequently amended and run, remains in our original solution. This separation means that the duration of activities like cloning, committing code and solution load-time are all positively influenced.
Conclusion
There is no doubt that working on legacy projects can come with a few headaches. Talking to developers from other teams, I have come to suspect that many mature projects struggle with similar deep-seated problems that feel impossible to overcome. I hope that I have demonstrated that these issues need not be permanent, and can be rectified with persistence and a few clever hacks.
Old code presents the greatest opportunity for developers to add the most value, and it is in these projects where improvement is most tangible.
If you've had a similar experience, I would love to hear how you went about tackling the beast that is anti-patterns.
Regan Koopmans is a Software Engineer currently working at Entelect Software out of Pretoria, South Africa. He likes long walks on the beach and is interested in clean code, functional programming and distributed systems.
