Upgrading the central database of a complex two-sided marketplace platform is not an easy task. Before we launched into this at Offerzen, the platform engineering team made a detailed playbook to help us navigate any issues. Here's how we did that.
OfferZen is a tech job marketplace that helps developers find awesome jobs and companies find great new team members. The platform team at OfferZen is responsible for:
- Deployments and infrastructure
- Tooling that abstracts complexity from our application developers
- Site reliability
Our platform spans multiple services and supports both internal and external users. Teams at OfferZen are free to choose the tools they want to work with and the platform team helps to get these tools into our ecosystem safely, so that our stakeholders can maintain their high level of productivity.
Our primary stakeholders are the:
- Teams in charge of building the web application
- Data team responsible for Business Intelligence (BI), Data Science and Data Engineering
- Marketing team
How we use MongoDB
At the heart of the platform is our Mongo Database (MongoDB). It powers a significant part of our business. If you’ve used OfferZen before, you’d be familiar with building your profile and interacting with potential new team members or employers. All these interactions and features are primarily supported by MongoDB. There are other database services we use to provide a world-class search experience such as Elasticsearch, Amazon Redshift and Postgres, but they still rely on MongoDB.
One of the advantages of having a third party host for your database is that they take care of the day-to-day maintenance of your clusters, patching them as new security updates become available. Our provider was dropping support for the version we were using, so we had to upgrade our clusters to the latest MongoDB.
Given how many parts of our platform are linked into MongoDB, any mishaps during an upgrade would have negative effects on the marketplace as a whole.
That’s why we went into a thorough discovery process.
The discovery process - creating a playbook
In the sports world, teams use playbooks to map their strategies and details of what to do in best and worst-case scenarios during a game. In the event that the team is doing badly, coaches will refer to the playbook to see what plays they can use to remedy the situation.
In a talk the platform team attended, a South African e-commerce marketplace, Takealot, mentioned how they used a comprehensive playbook for their migration from a locally-hosted kubernetes solution to the Google Cloud Platform. We immediately saw the value of creating a playbook for our MongoDB upgrade process to ensure that we could safely upgrade our database.
The playbook would help us identify the necessary resources we needed, as well as actions to take should things start going wrong.
Just like the sports teams, we would be able to practice our playbook beforehand to mitigate any risk of downtime.
Mapping out the problem space
Now we had to map out all the services that make use of our MongoDB cluster on Miro and get a good idea of how all these connected systems interacted with the database:
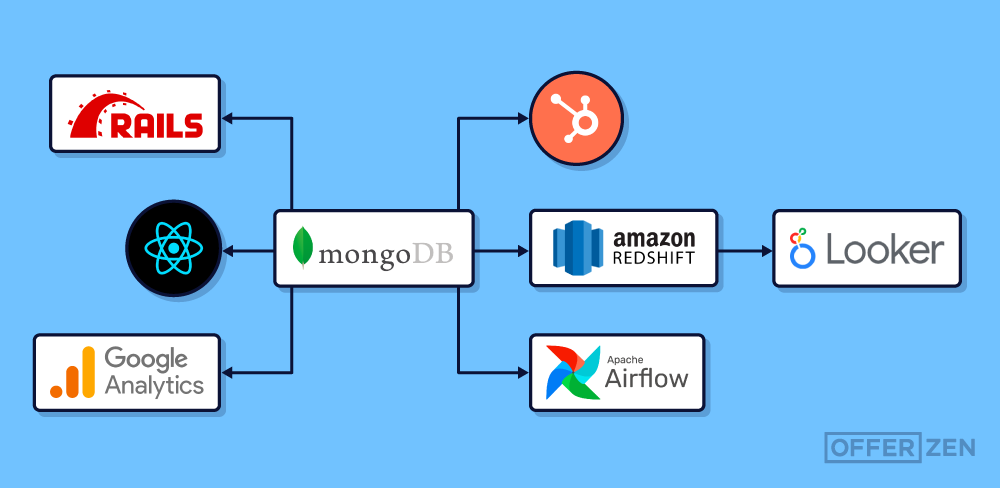
We realised that the main system that would be affected by the upgrade was our web application built with Ruby on Rails. It makes use of the Mongoid gem to interact with our database. For all our write operations to MongoDB, we use Mongoid. Thus, all we had to do was to upgrade the database version in our local, test and staging environments. Our Rails application has good test coverage, so we were confident that the upgrade itself would not corrupt any of our data.
“Tests and testing environments are invaluable to us as the platform squad. Without them life would be unimaginable”
Running the target version in the test and staging environments:
As part of discovery, we spent a period of two weeks running the target version in our test and staging environments while we worked on the playbook we would use. We mapped out all the possibilities and from there we did a first pass of that playbook, making changes along the way. After getting to the end of the first pass which took us the better part of a day, we resumed the next day to run through the playbook again. The subsequent runs became faster as we became more familiar with where everything was.
Another finding from our discovery process was that our database hosting provider Atlas only allows upgrades one version at a time. To get to our target version, we had to upgrade to an intermediate version before upgrading to the target version. Atlas has great tooling for performing upgrades, but you can never be too prepared.
That’s why we decided to create two backup clusters: One would contain a snapshot of the current version, the other would be used to store a copy of our database at the intermediate version and the final cluster. If something went wrong, we would be able to fall back to one of the backup clusters and it would serve as production.
At the end of our discovery process, our playbook looked like this:
- Create two backup clusters
- Take a snapshot of the current DB and restore it to the first backup cluster
- Run tests to make sure that the restoration process was good
- Upgrade production to the intermediate version
- Run tests on production to make sure that the upgrade worked
- Take a snapshot of the production at the intermediate version and restore it to the second backup cluster
- Upgrade production to the target version
- Run tests on production to make sure that everything is working well
We ran through the playbook and took note of the times each step would take. We also paired up during the practice session. Pairing provided a great way to identify potential issues with a colleague to make sure we did not miss anything.
Adding crisis scenarios to the playbook
We then expanded the playbook to take into account what would happen if a failure were to happen at any step. By the time we finished the second iteration, the playbook had changed to this:
- Create two backup clusters
- Any failure here; we abort the whole process and contact Atlas
- Take a snapshot of the current DB and restore it to the first backup cluster (cluster 1)
- Any failure here; we abort and contact Atlas
- Run tests to make sure that the restoration process was good
- Any failure here; we abort and contact Atlas
- Upgrade production to the intermediate version
- Any failure here and cluster 1 becomes production. We update all services in our infrastructure with cluster 1’s credentials and contact Atlas
- Run tests on production to make sure that the upgrade worked
- Any failure here and cluster 1 becomes production. We update all services in our infrastructure with cluster 1’s credentials and contact Atlas
- Take a snapshot of the production at the intermediate version and restore it to the second backup cluster
- Any failure here and cluster 2 becomes production. We assume production is broken if we cannot create snapshots. We update all services in our infrastructure with cluster 2’s credentials and contact Atlas
- Upgrade production to the target version
- Any failure here and cluster 2 becomes production. We update all services in our infrastructure with cluster 2’s credentials and contact Atlas
- Run tests on production to make sure that everything is functioning well
- Monitor cluster and applications for a couple of days before destroying the backup clusters
“Practice, practice, practice. We were able to identify some problematic areas in our playbook during practice and addressed them accordingly”
Final preparations
Once we were confident of the process, we needed to find an appropriate date and time to perform the upgrade. We use Datadog for our monitoring and it was quite easy to look for three options around the quietest times that would be least disruptive for our users.
Atlas does support rolling upgrades for their clusters, but they recommend limiting writes during upgrades. Since the integrity of our data was of paramount importance, we decided to stop all traffic going to our database during the upgrade. This meant notifying the rest of the OfferZen team so that they could tell us if our window was going to disrupt their work.
Since we operate in Europe as well, we wanted to make sure that our operations teams would not be trying to access some critical resources during the upgrade. Thankfully, this meant a simple broadcast message to one of our Slack channels that gave us immediate feedback. We also took the opportunity to share our playbook with the whole product team and get feedback on it.
We eventually settled on a one-hour-window on a Saturday morning between 6am and 7am. Before the day, we set up the backup clusters and notified the company of the downtime.
Apart from two platform engineers, our Head of Tech and Chief Technology Officer decided they would also join on the day. Our guiding principle for the day was to make the process boring and uneventful. Fighting fires during a database upgrade is not something anyone wants to do.
The delivery
On the morning of the upgrade, we were in the designated Zoom room by 05:45 SAST with coffee in hand and all the necessary applications open. The first part of the playbook involved redirecting all traffic that goes to our application to head over to a maintenance page. Our marketing pages were still being served since these are not linked to our database.
One platform engineer drove the process while the other navigated and kept track of the time. Pairing on the process was hugely beneficial as it really took the pressure off the upgrade process. It helps to know that your colleagues are there to double-check each step and that if anything goes wrong, you have support.
We performed the first steps of the playbook and boom! Our first unexpected issue hit. We forgot to upload the images needed by our maintenance page to render the cool graphics made by our team. Embarrassed and knowing we would need to explain ourselves and bring donuts on Monday to the marketing team, we continued.
Since we had practiced our playbook multiple times beforehand, the process was truly boring and predictable. Halfway through the process we fell a few minutes behind schedule, but this was due to the fact that during our practice runs, the test databases were much smaller. Thanks to a thorough playbook, we had no need to panic and we had full confidence in our process.
We finished the upgrade process 10 minutes behind schedule and then went off to enjoy the rest of the weekend, while keeping an eye on our key metrics. On Monday, everyone could continue with business as usual. As the platform squad, we had done our job well.
The key takeaway from this process was that having a playbook is absolutely essential to running critical upgrades such as this.
The process of creating one highlights potential pitfalls long before you start and you are able to prepare for anything that comes up.
Like professional athletes, preparation is key for most of the work we do as the platform team. It goes a long way to be able to make changes more easily within a complex environment.
Engineering Lead Kenny Chigiga focuses on all things platform-related at OfferZen. When he’s not tinkering with the latest cool tech, you’ll find him road running or cycling. He loves to spend time outdoors with family and friends.