In e-commerce and other digital domains, companies frequently want to offer personalised product recommendations to users. This is hard when you don't yet know a lot about the customer, or you don't understand what features of a product are pertinent. Thinking about it as a multi-armed bandit problem is a useful way to get around this. In this article, I will explain how multi-armed bandit algorithms can be applied to the challenge of product recommendation and then explain how to solve it in code.

What is the problem of product recommendation with limited information and why is it such a difficult one?
Automatically recommending a product to a customer has become a fundamental part of many successful digital companies. They collect data on their customers' preferences and use various machine learning approaches to match up customers with the product that they are most likely to enjoy. "Wow," you think. "They've done a pretty good job!"
But what do companies do when they don't have any data on their customers yet? Instead of leaving their data scientists twiddling their thumbs, they may try and recommend a product they think customers will like or they could try sending out email campaigns to attract users to their website.
Exploiting the sure-thing, and exploring the unknown to gather more information both come with a trade-off:
- You don't take advantage of the products that you think would be more popular, because you're waiting too long to find out what works for your customers.
- Customers become irritated and don't return to your site, because you're biting the bullet and offering them something you only think they may like.
With limited information about what actions to take, what their payoffs will be, and limited resources to explore the competing actions that you can take, it is hard to know what to do.
How can we begin to tackle this problem?
In a situation where companies have more data – however limited it may be – on their customers, products and customer interaction, they can consider using some of the classic recommender systems:
- Collaborative filtering works by recommending things that similar customers liked. However, it suffers from the cold-start problem, which is when there are new products that no one has used or liked.
- Content-based filtering matches up content or products based on their attributes to a customer's preferences.
You can read more about these approaches in Helge's blog post. Although both of these algorithms work well under certain conditions, neither of them are appropriate when companies have no data whatsoever.
Multi-armed bandit algorithms, however, can offer a solution because:
- They can recommend products with the highest expected value while still exploring other products.
- They do not suffer from the cold-start problem and therefore don't require customer preferences or information about products.
In addition, multi-armed bandits take into account the limitations of how much data you have as well as the cost of gathering data (the opportunity cost of sub-optimal recommendations).
The name multi-armed bandit comes from the one-armed bandit, which is a slot machine. In the multi-armed bandit thought experiment, there are multiple slot machines with different probabilities of payout with potentially different amounts.
Using multi-armed bandit algorithms to solve our problem
Having determined that we have no data on our customers and products, and therefore cannot make use of classic machine learning approaches or other recommender methods, we must apply a multi-armed bandit algorithm to our problem.
To get started, we need to lay the groundwork to understand what we are working with so that we can employ the most useful algorithm. While we might not have much data, there will be some foundational things we can consider to help us make a start. Think about the following:
- What is the product that you are recommending? Are there any features about it that you think might be relevant in the future? This could be useful if later down the line you want to use classical recommender systems or contextual bandits.
- What is the customer behaviour? At the very least you need to know whether or not someone interacted with the product – and how. Was it presented to them? Did they like or buy it? This is necessary for any recommender system.
- What is the reward or payoff? This can be the revenue, profit, a "like", or user rating – anything that you want to maximise the value of. This is a prerequisite for using multi-armed bandit algorithms.
After you have taken these factors into consideration, you can start applying multi-armed bandit algorithms and will be well set up to make use of the data you gather.
Some multi-armed bandit algorithms written in code.
Let's try out some algorithms! In this section we'll look at some simple examples to help develop our intuition about when and how multi-armed bandit algorithms will be relevant.
First, we'll set up our own multi-armed bandit problem simulation that will allow us to sample rewards randomly based on the payoffs of the different actions.
We are encoding a toy example of what a real-world situation with different probabilities of a payoff would look like to our algorithms.
Then, we'll create a few "agents" that will each represent a different strategy to maximise the total reward from the multi-armed bandit.
"Explore-first" greedy
If you're ever faced with a problem and don't know what to do, you need to first explore your options.
One of the easiest ways of solving this problem is the explore-first approach, where for some period of time you just randomly perform actions and note the payoffs. Then, you pick the one with the highest average payoff and exploit it. That's where the "greedy" comes from. Easy! You wouldn't necessarily follow this strategy in a real-world situation, but a major advantage is its simplicity. Hopefully our other approaches will beat this one.
The issue with using this algorithm is that you don't know how long you need to explore since it might take awhile to figure out the best action to perform. Another issue could be that by chance you picked the wrong option and stopped exploring too soon!
Epsilon greedy
If you don't have the luxury of a long exploration, you can use a more technical approach. The epsilon greedy algorithm allows you to only explore random actions with ε (epsilon) probability. Otherwise, with the probability of 1 - ε, you pick the action with the best average payoff. You can even start with an explore-first phase for a few iterations.
The reasoning behind this approach is that for a portion of the time the algorithm randomly explores the available actions, but it still exploits the best action the majority of the time.
You can do even better and say that ε should become smaller over time, since after a period of time you wouldn't want to randomly explore as much anymore. If your customer behaviour is unchanging, you should have built up a good idea about their preferences. In that case, you multiply ε with some "decay" factor. This value will cause the epsilon value to decrease over time.
There are other approaches out there and even some that have performance guarantees that hold under certain conditions – but we won't go into that level of detail here. These algorithms above are a good entry point into the world of multi-armed bandits.
Develop your intuition by plotting experiments.
Once you've coded enough algorithms, you can run some experiments! You can compare your algorithms to a random agent that has no strategy as well as an optimal agent that cheats by performing the action with the best payoff. You'd want to do this before running the algorithms in a real-life situation, in order to better understand their limitations and how they would perform in your application.
We are going to test out our toy example with some made-up payoffs. In practice, you wouldn't know what these payoffs are, but you would still be able to simulate different situations.
In this case, to make sure we capture the variability of the random system, we do 50 trials with 200 iterations for each of the strategies. An iteration here is one round of picking an action for the multi-armed bandit, and, with each trial we start from scratch at iteration 0.
The result of this experiment can be seen below. The average reward for each iteration is plotted with a confidence interval using seaborn lineplot.
You can see that the initial-explore agent has a lot more variation in its outcomes since it sometimes picks the wrong action; it needs more exploration first. For this simulation and example, the epsilon greedy and decaying epsilon greedy algorithms performed better. The customer behaviour didn't change at all so a decaying epsilon helped.
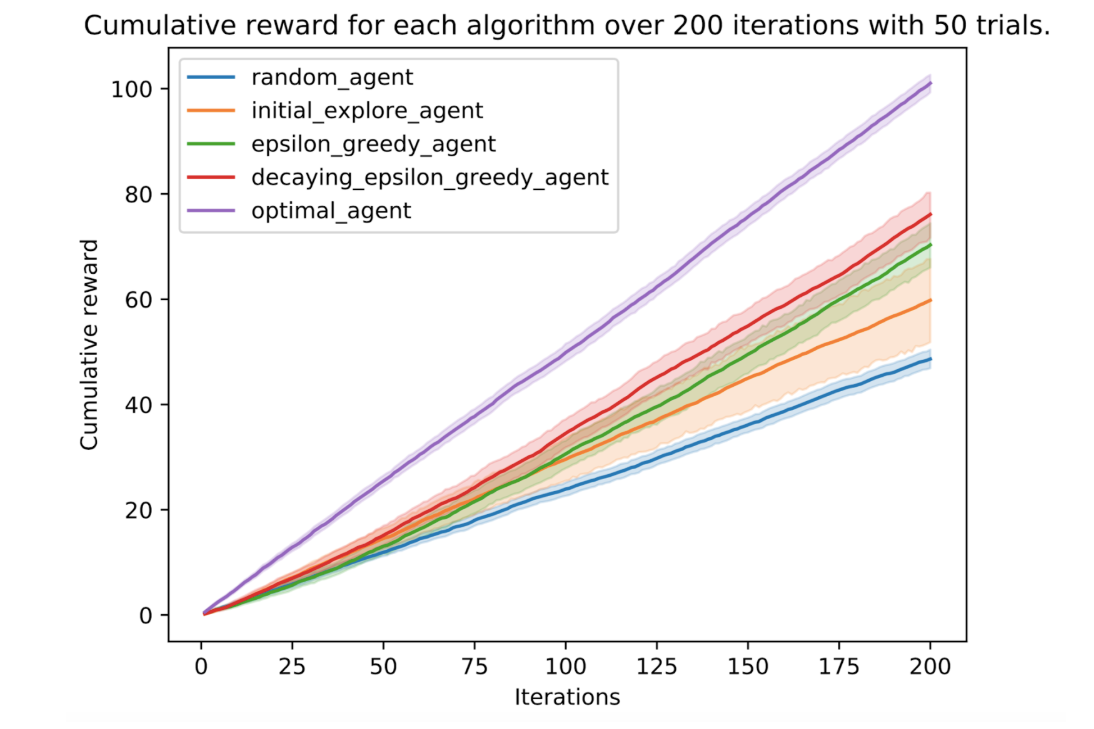
A classic machine learning approach would not have been able to make those initial recommendations that allowed the multi-armed bandit to pick up on the correct action to perform. Classic recommender systems would also not be able to function under the assumptions we made of not having information on either our products or customers.
The code used to demonstrate the concepts of the multi-armed bandit algorithms can be found here.
A recap of the advantages of multi-armed bandit algorithms
- They can handle the cold-start problem.
- They automatically balance the explore-exploit trade-off to maximise your reward.
- There can be different probabilities of a payoff as well as different payoff values that could even change over time.
- They can recommend multiple actions (although we only explored algorithms that give a single action to perform).
- They are simple to implement and allow you to start gathering data.
How to improve on these algorithms
The algorithms that we looked at are quite simple and easy to implement. However, there are more advanced techniques that have been developed and some that are freely available to use.
One such approach is the upper confidence bound multi-armed bandit algorithm. It is an algorithm that is "brave" in its exploration approach and tends to favour actions that have a high uncertainty surrounding their payoffs. That way, when exploring, the algorithm avoids the options that it already knows have a low expected reward and makes sure it learns about the unexplored options quickly. Thompson sampling, on the other hand, uses a more sophisticated approach involving Bayesian probability theory.
Once you have some features about your customers, or other information about the environment in which your products are recommended, you can start looking at contextual bandits. These algorithms take the "context" into account that enable you to allow for individual customers' information (but that can be best left for another time and another blog post).
Ultimately, you need to do some exploration to look at your problems and the different potential solutions and see what works best for your context – just like a multi-armed bandit algorithm!
Using machine learning techniques in data science is helpful, but what is most important is understanding the problem that you are trying to solve.
Resources
If you are interested in trying out more code for multi-armed bandits, or taking a deeper and more theoretical approach, have a look at the resources below:
-
Blog posts and a book about bandits.
-
Code for the book Bandit Algorithms for Website Optimization.
-
Bandits Python package.
Charl de Villiers is working as a data scientist at a South African telecommunications company. He has an engineering background, with a master's degree in electronic engineering with a focus on digital signal processing and machine learning from Stellenbosch University. He loves working with data: wrangling it, understanding it, and ultimately gaining insights and making predictions from it. He is always looking for a machine learning/signal processing challenge.
