Traditionally, programs are code first with maybe some blocks of prose in the form of code comments. If you then write an article about a program, you might copy some of the code out of that program to illustrate your point. What if we turned this on its head and started with the prose? What if we only wrote the code as it became relevant to the article? What if my blog articles were executable?
Today, I want to share a programming paradigm that I’ve been using when I write about software. It’s called Literate Programming, and it’s changed the way I think about writing.
What is literate programming?
What’s the difference between writing and programming? When I sit down to write something, I don’t typically reach for a pen and paper, but rather sit down at my computer and start rhythmically tapping at the keyboard. It sounds a lot like programming. I’m a software engineer by trade, and in the last few years I’ve been blogging about programming.
I think that there is great potential to enhance both writing and programming by allowing the lines between them to blur from time to time.

Literate programming isn’t something that many modern software developers seem to have heard of, but it isn’t a new idea. The term was coined in 1983 by Donald Knuth to refer to the new way in which he was laying out his software projects.
Usually, when you think of how a software project is organized, the first consideration is what the compiler expects. You split things into files and folders in a particular way. You name the functions concisely and without spaces. Software engineering tools have luckily gotten much better since 1983, including neat features like function names longer than six characters. You can even define functions in any order you please, and have clever IDEs figuring out variable types when you hover your mouse over them. The structures that suit the compiler have become more flexible and more human friendly.
For long running projects, there’s a non-compiler audience you need to consider: the software engineer who encounters the code you’re currently writing. We’re still looking at folders full of source code and we’re fighting a battle to make it clear to future readers what problem each bit of code is solving. Have you ever needed to debug code that was written five years ago, by someone who has since left the company? When you suspect it isn’t working but can’t figure out exactly what it was meant to be doing in the first place?
Knuth felt that there was a more effective traditional solution to explain these things: books. Imagine if you could hand your new coworker a book and say “this explains exactly how our system works”. Knuth also created the TeX typesetting system, so he was in the perfect position to come up with a clever scheme to combine writing prose and writing code:
The source code for a literate program looks much more like a document than normal source code. The key feature is that there are blocks of code embedded directly into the document. You can pass your literate program to one of two compilers.
The first compiler produces a nicely typeset human readable document (more recently a nicely typeset human readable web page). That would be the document you’re reading right now. If I drop in a block of JavaScript, it might look something like this:
console.log('Hello world!');
The second compiler takes just the code blocks, stitches them together, and calls the normal compiler. For JavaScript, that means calling Node JS. I could run that program, and get the expected salutation.
Hello world!
To go beyond a hello world example, I recently wrote an article where I explained how Monte Carlo simulations work. In the article, I had a code block with an example written in the Rust programming language. It used a Monte Carlo simulation to calculate Pi. I could compile and execute that blog article to run the simulation and show the results. I could even automatically insert the console output from the simulation into the article itself.
In other words, you write a document that describes your program, and that document is also the source code for the program being described.
My literate toolbox: Emacs Org-mode
For literate programming, I use a language called Org-mode. I know, the name is a bit strange, but it makes more sense if you consider its history. Org-mode started as an extension for the text editor Emacs that helped to organize notes. Emacs users have found it so useful that now it’s part of the base install.
At its heart, Org-mode is a plain text format similar to Markdown. You put some stars at the beginning of a line and suddenly that line is considered a heading! The organization elements come in where you start a line with TODO and suddenly that line is an item on your to-do list. I could easily fill a series of articles on things I do with Org-mode, but for today I’m going to focus on its literate programming support.
When you want to export your Org-mode file for people to read, it supports many different formats. This means it can be a good option regardless of where you need the notes to go in the end. I personally use three:
- HTML for my website,
- PDF (via LaTeX) if I want something printable and
- HTML in reveal.js format, for when I’m making presentation slides.
In terms of programming languages, Org-mode supports writing code blocks in a great many programming languages, including a template to add support for your favourite one.
All of this becomes a lot more relatable with an example.
Let’s write a quick literate program
For this example, say that you’re teaching a course. You have a class list of students, and the marks that they received. You need to write up a report on which students passed and which failed. Additionally, you need to calculate some statistics to get an idea of how well the course went.
Rather than reaching for separate writing and programming tools, you decide to do your report as a literate program.
I know that this is an overly simplistic example. This obviously doesn’t show Org-mode working at its limits, but rather just a silly example to get you thinking about what’s possible.
Setting up your environment
I’m going to use JavaScript as the programming language in this report. It’s a fairly well known language, and its dynamic nature means that the examples don’t get as bogged down in ceremony.
If you’re following along in Emacs, you’ll need to enable the integration between Org-mode and JavaScript. You can do this by adding the following line to your Emacs config:
(require 'ob-js)
You also need to have Node.JS installed on your computer. This is the normal situation for any programming language you want to support in Org-mode. First, you need the tools to execute that language installed on your computer. Then, you need to tell Emacs how to call it by adding something like that require statement to your Emacs config.
Finding data to work with
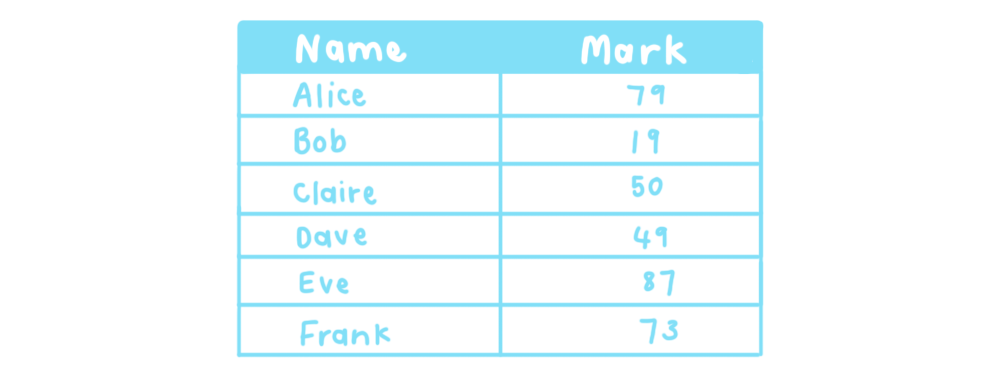
The first thing that you’ll need to do is get the data that you’re interested in working on into Org-mode. You also need to name the table, so that you can refer to it in scripts later. I’ve named this table “students”. This is the syntax for a table:
#+NAME: students
| Name | Mark |
|--------+------|
| Alice | 79 |
| Bob | 19 |
| Claire | 50 |
| Dave | 49 |
| Eve | 87 |
| Frank | 73 |
Org-mode makes it easy to create a table from CSV if you happen to already have the data in a different format.
Once you export it, it’s just a normal table.
Our first code block: what does it mean to pass a course?
Let’s start writing some code. The first thing you’re going to do is to write a function to determine if someone has passed. In a real course, maybe you need to add up marks from multiple assignments, or maybe students need to pass all of the assignments leading up to the exam as well as the exam itself.
The beauty of it just being a code block is that the function can get as complicated or simple as it needs to be.
For your class, a student has passed if their mark is more than 50%, plus an extra 5% required for every letter of their name. Bob and Eve are faster names to type, so their marking can be more lenient. You should also give this code block a name so you can reference it later. I’m naming it “passes functions”.
This weird logic for marking is something that you might code up and then forget about.
One of the strengths of literate programming is that it gives you space to capture business decisions and the reasoning behind them.
The Org-mode syntax looks like this:
#+NAME: passes functions
#+BEGIN_SRC js
function isPass(student) {
return student.mark >= requiredMark(student);
}
function requiredMark(student) {
return 50 + student.name.length * 5;
}
#+END_SRC
With all of the Org-mode examples here, I’m including both the Org-mode source code and the results of exporting it. Whenever you see #+BEGIN_SRC js, you’re looking at Org-mode source code. The “js” tells Org-mode that it’s JavaScript code.
Like with the table, it’s rendered into your exported HTML report, complete with appropriate syntax highlighting.
function isPass(student) {
var name = student[0];
var mark = student[1];
return mark >= requiredMark(name);
}
function requiredMark(name) {
return 50 + name.length * 5;
}
Let’s find out who passed
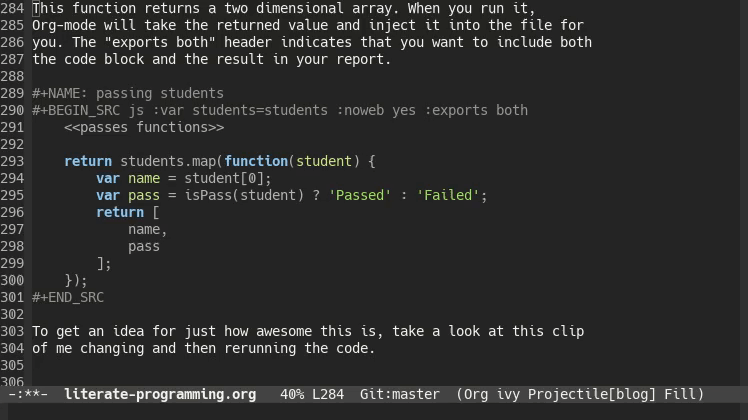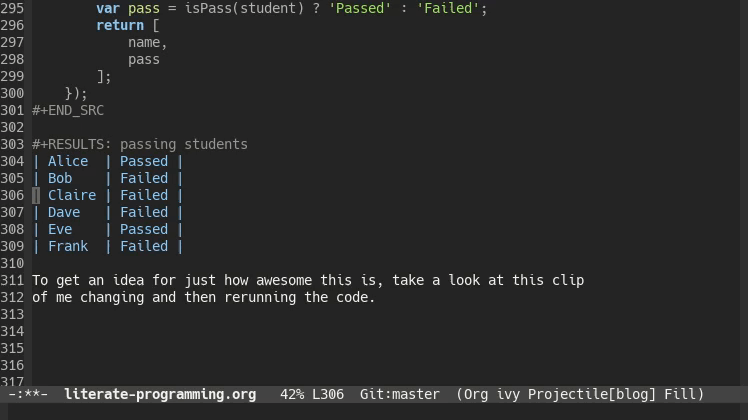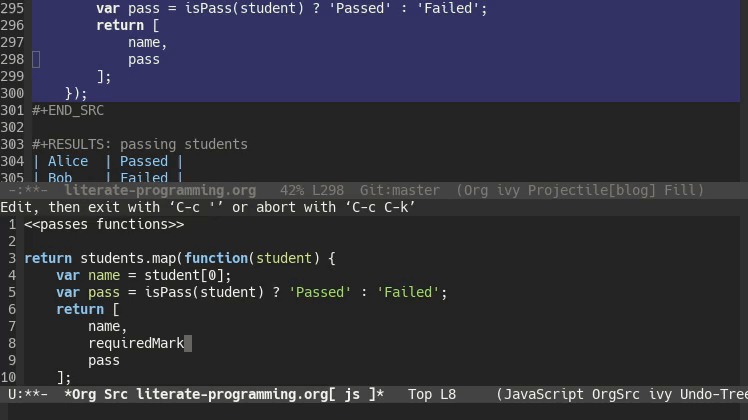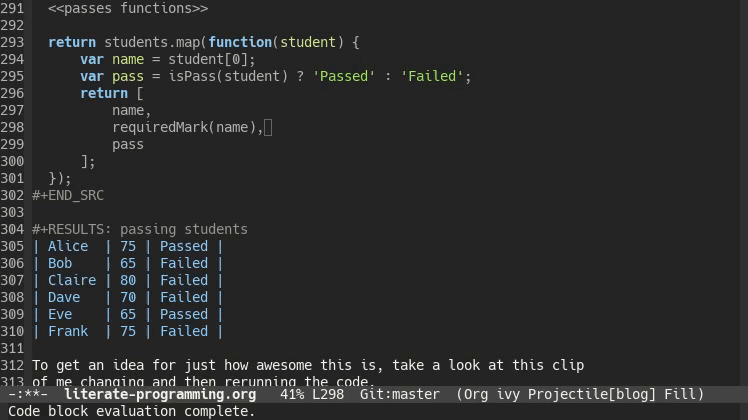
Having set up a table of students as well as a way to tell if they pass, you now need to make a new table that lists the passes and failures.
This code block uses two new things. The first is that I’ve declared a variable in the header of the code block called “students”, and pass in the students table from earlier. The second is that I use “noweb” syntax (named after Knuth’s Web program that he wrote for literate programming), to inject my passes functions into the code block. You can think of it as the compiler copying the “passes functions” block and pasting it in the “<<passes functions>>” in this block.
#+NAME: passing students
#+BEGIN_SRC js :var students=students :noweb yes :exports both
<<passes functions>>
return students.map(function(student) {
var name = student[0];
var pass = isPass(student) ? 'Passed' : 'Failed';
return [
name,
pass
];
});
#+END_SRC
When you export, the headers from the code blocks aren’t rendered. A reader won’t necessarily know what the passes functions are. Usually, this isn’t a problem because you can clarify this in your prose.
This function returns a two dimensional array. When you run it, Org-mode will take the returned value and inject it into the file for you. The “exports both” header indicates that you want to include both the code block and the result in your report.
<<passes functions>>
return students.map(function(student) {
var name = student[0];
var pass = isPass(student) ? 'Passed' : 'Failed';
return [
name,
pass
];
});
To get an idea for just how awesome this is, take a look at this clip of me changing and then rerunning the code.
The table is just another Org-mode table. You could have another code block reading in the results of this one. It even works if your second code block is a different programming language. This lets you use different programming languages for their various strengths. Have a program written in C++ that generates data but you want to analyze the data using R? After you’re done with the analysis you want to use Gnuplot or Graphviz to represent your findings graphically? Org-mode has you covered!
Using code that hasn’t appeared yet
Sometimes, when you’re writing a report, you want to skip straight to your results. In this section, let’s jump straight to showing the average and standard deviation of the marks.
Count: 6
Average: 60
Standard deviation: 25
The Org-mode code that generates the results looks like this:
#+NAME: overall statistics
#+BEGIN_SRC js :var students=students :noweb yes :exports both :results output
<<statistics functions>>
var marks = students.map(function(student) {
return student[1];
});
console.log('Count:', marks.length);
console.log('Average:', average(marks));
console.log('Standard deviation:', standardDeviation(marks));
#+END_SRC
When you execute this block for the first time, Org-mode will inject the console output from your code into the report below your code block. Crucially, the results will have a header indicating the name of the code block that produced it. In Org-mode, it looks a bit like this:
#+RESULTS: overall statistics
: Count: 6
: Average: 60
: Standard deviation: 25
You can then move the results block to wherever you want in your report:
In a literate program, the code blocks and their results are linked through their names. They don’t need to appear in a particular order in the report.
This frees you up to organize the code in your report as would make most sense to a reader. You can even update and rerun the code and see the results update!
In the end, I have my code block that produced those results down here, but the results are a few paragraphs up.
<<statistics functions>>
var marks = students.map(function(student) {
return student[1];
});
console.log('Count:', marks.length);
console.log('Average:', average(marks));
console.log('Standard deviation:', standardDeviation(marks));
You might notice that I used a code block here that hasn't been introduced yet: The code that actually does the average and standard deviation calculations is in a code block later on called “statistics functions”.
When I was in university, my project reports had strict page limits. My entire report had to fit into 5 pages. I was, however, allowed to include an appendix for peripheral details of importance, such as:
- Raw data,
- Full code listings and
- Blocks of code explaining how to implement well-known statistical functions in JavaScript.
I use the "statistics functions" code block in a very similar manner.
Excluding statistics functions from your report
As promised, the statistics functions have to be somewhere in the report. I’ve included them here, but I’ve chosen to set the exports header to “none”, so that it wouldn't be included in the HTML export. For the sake of this example, I’m saying that these functions aren’t particularly important to readers.
#+NAME: statistics functions
#+BEGIN_SRC js :exports none
function average(marks) {
return Math.round(marks.reduce(function(accumulator, next) {
return accumulator + next;
}, 0) / marks.length);
}
function standardDeviation(marks) {
var marksAverage = average(marks);
var sd = Math.sqrt(marks.reduce(function(accumulator, next) {
return accumulator + Math.pow(next - marksAverage, 2);
}, 0) / (marks.length - 1))
return Math.round(sd);
}
#+END_SRC
Time to Tangle
The term “tangling” is another word borrowed from Knuth. He named his literate programming tool Web because the connections between code blocks are so web-like. That's why, when you compile a web program into a human-readable document, it's called weaving.
When you compile a web program to an executable program, it’s called tangling.
Whenever I want to test a code block for my articles, the Org-mode file is tangled and executed. When I want to view the article in my web browser, the Org-mode files are weaved to produce my website.
In this example, I focussed on letting Org-mode take the code block and execute it. If you add the “tangle” header to a code block, you can tell Org-mode to write it out as a file. This can be particularly useful if you’re writing one literate file as part of a larger project.
#+BEGIN_SRC js :tangle passCalculator.js
function isPass(student) {
var name = student[0];
var mark = student[1];
return mark >= requiredMark(name);
}
// Other JavaScript here as before
#+END_SRC
After telling Org-mode to tangle this code block, it will be written out to the file passCalculator.js. This is particularly useful if you have an existing system that you're extending using literate programming. You can write your new files in Org-mode, and have it tangle your code blocks into the appropriate file structure for your
existing system.
What are the benefits of literate programming?
At this point, you might be asking yourself why you should put in the effort to learn a new tool. Well, as Knuth said, “Surely nobody wants to admit writing an illiterate program.” Jokes aside, if you spend your time writing prose, you might be suspicious of bringing executable code into your writing. On the other hand, if you spend your time writing software, you might be suspicious of bringing in more documentation. Let’s look at the benefits to both sides:
As a developer, I think the benefits that literate programming can bring for everyday programming have been slowly eroded by advancements in modern language design. However, literate programming is still valuable if your problem domain is very complicated. Well written code alone is very good at explaining what it is doing, but very bad at explaining why it’s doing it.
If you don’t understand the why, you will have a particularly miserable time if you need to adjust the code to meet changing requirements.
Suppose you’re writing a library that makes heavy use of some particular mathematical theory. Everything would be much clearer to a future programmer if they knew about the theory first. Literate programming’s focus on organizing the program to be read like a book could be extremely valuable. Recently, I wrote a financial planning library at work. Even though it isn’t that much code, it was the result of a few months of back and forth with an expert in our business domain.
Code alone cannot hope to capture all of the derivations, reasoning and trade offs that went into the final result.

The writing side is where I’ve personally seen the most benefit, which I group broadly under the term “reproducible research”. If you’re writing a report that at any point references some number crunching, having the actual code that did the number crunching in your document makes it easier for readers to understand how you reached your conclusions. It also makes it much easier to rerun your calculations if a bug is found. I also find that having the code as part of the document lets you jump between describing what you need to do and implementing it, without having to make quite as big context switches.
These are the same benefits that you might get by using a spreadsheet. If you’re already in a spreadsheet, you’re much more likely to drop in a calculation here and there, and let the computer do the heavy lifting. Once your calculations are there, future readers can see how you reached your conclusions. In fact, you could probably consider spreadsheets to be a form of literate programming.
What about the downsides of literate programming?
Up to now, I’ve been talking about literate programming as if it’s a magic panacea that will solve all of your software engineering woes. Unfortunately, this isn’t the case with any technology or programming paradigm.
Sometimes as a software developer, the majority of your application is fairly obvious. There are many web applications that take data from a user and store it in a database without any special processing. In these cases, the extra overhead of writing thorough documentation probably isn’t worth the effort.
As software developers, we have a nasty habit of letting any existing documentation get out of date. Writing your software as a literate program needs to come with a strong commitment to keeping that documentation up to date. Unfortunately, having a good understanding of what the software used to do isn’t always useful. Having the code and documentation together in one tools helps, but it doesn’t take away the extra effort needed.
On the writing side, the main issue is that literate programming tends to tie your writing into the tools that support your literate programming. This can make collaboration on a document difficult if the people you’re collaborating with are not as sold on the tools as you are. The moment you need to work with a business person who prefers to use Google Docs to share a document, or a university department that insists on receiving drafts as Microsoft Word documents, you start to face the pain of exporting to those proprietary formats. Like many issues in software development, this is really a social issue: for literate programming to work, all of the writers need to agree on the tools being used.
Coding is a social activity
Hopefully, I’ve been able to show you that it’s worth your time to take a look at literate programming and Org-mode. It can make your programming more expressive. It can give your writing the powers of your favourite programming language.
And most of all, in all of this jargon and code, don’t forget the human aspect of programming. When you’re pushing to get another feature out or squash another bug, it’s easy to get tunnel vision and see only the code in front of you.
Sit up and look at the people around you. They are the ones that you’re writing your code for.
The code you’re writing today has the potential to be easy for them to understand and a pleasure to work with. As my coworkers will attest, I don’t always manage to get this right. When I manage to write code that others enjoy working with, that is a particularly rewarding feeling.
Remember literate programming. It might not be the best solution to every problem you encounter, but sometimes it is exactly what you need.
Addendum: What if I don’t like Emacs?
Ok, I admit, Emacs isn’t everyone’s cup of tea. It’s an expert friendly tool with a steep difficulty curve. If you don’t have the time or patience to go through the process of learning Emacs, there are other options available.
Spreadsheets
The easiest option is to use a spreadsheet program. Spreadsheets are more capable than most people realize. They have a broad array of built-in functions, they’re interactive, and people you’re collaborating with have probably used one before so they’ll be able to follow what’s going on.
For me, they fall flat on two points:
- They’re clunky when you’re trying to do something complicated that isn’t already supported out of the box.
- It’s difficult to export the code itself rather than the results.
Haskell, and other languages that just support it
It’s a bit uncommon, but some compilers already support literate programming. I don’t personally use Haskell, but apparently you just need to use the .lhs file extension rather than the usual .hs.
Online document editors
Jupyter lets you create notebooks that have embedded Python, Julia or R code. It’s different from Emacs and Org-mode in that it runs entirely in your web browser.
Tech.io also lets you create documents with embedded code blocks in your browser. It’s meant primarily as a tutorial and documentation site, so readers are able to modify and rerun the code blocks themselves. This approach can be fantastic for documentation that explains how to use the code you’ve written.
Command line applications
If you like working in a text editor but don’t like Emacs, then finding a command line application could be the right option for you.
You might still be able to find Knuth’s original application called Web, but Knuth himself has moved on to a newer version called CWeb.
If you go looking, you’ll find a few more variants with the same play on words, such as Noweb, which tries to be simpler to use than Web.
How can I learn more?
If you’re thinking of trying out literate programming after reading this, maybe one of these links will help you to find a good next step:
- The Emacs project’s website, to download Emacs.
- Getting yourself organized with Org-mode is a series of Youtube videos explaining how to use the various functions of Org-mode.
- Org-mode’s documentation on literate programming, for more examples of things you can do with Org-mode.
- Donald Knuth’s original paper, where he coined the term Literate Programming.
- CWeb, Donald Knuth’s favourite programming language (this site also has examples of people using CWeb to write literate programs).
- Jupyter, a notebook in your web browser that lets you embed Python, Julia or R.
- Tech.io lets you create and share source code blocks that your readers can modify and execute, great for tutorials.

Justin Worthe is a software engineer with an interest in music, games, good coffee, and using programming to get stuff done. He can often be found trying to find ways to play with all of these interests simultaneously. In the meantime, you can catch him on Twitter or Github.